Différences entre versions de « Big Data »
| Ligne 56 : | Ligne 56 : | ||
|Typologie= <!------------------------------------ Ne pas Modifier --> | |Typologie= <!------------------------------------ Ne pas Modifier --> | ||
<!-- ****************** Commercez les modifications ****************--> | <!-- ****************** Commercez les modifications ****************--> | ||
| − | {{@}} Le [[Big Data]] | + | {{@}} Le [[Big Data]] a été initialement caractérisé par les « 3 V» de '''V'''olume, '''V'''ariété, '''V'''élocité. |
* '''Le « Volume » du [[Big Data]]''', soit la quantité de données à disposition, est colossale. Elle se composerait de plus de mille deux cent milliards de milliards d’octets, dont 90 % ont été produits dans les deux dernières années, et ce chiffre devrait doubler tous les deux ans. Le volume joue un rôle capital, en effet la justesse des informations dégagées dépend de la quantité de données traitées. On ne cherche plus à travailler sur un échantillon mais sur tous les cas réels d’un phénomène donné. On comprend alors le puissant mouvement de recueil des données, qui s’accommode mal de la nécessité d’attendre des consentements individuels. | * '''Le « Volume » du [[Big Data]]''', soit la quantité de données à disposition, est colossale. Elle se composerait de plus de mille deux cent milliards de milliards d’octets, dont 90 % ont été produits dans les deux dernières années, et ce chiffre devrait doubler tous les deux ans. Le volume joue un rôle capital, en effet la justesse des informations dégagées dépend de la quantité de données traitées. On ne cherche plus à travailler sur un échantillon mais sur tous les cas réels d’un phénomène donné. On comprend alors le puissant mouvement de recueil des données, qui s’accommode mal de la nécessité d’attendre des consentements individuels. | ||
| Ligne 63 : | Ligne 63 : | ||
* '''La « Vélocité » du [[Big Data]]''' caractérise à la fois la rapidité de production et de traitement des mégadonnées. C’est le « data mining », qui permet de traiter rapidement les masses de données grâce aux algorithmes. Ces outils d’analyse, de plus en plus puissants, sont capables de s’autocorriger (« machine learning »), gèrent des informations qui n’ont plus besoin d’être structurées dans des bases de données, et permettent de détecter des relations entre des données hétérogènes provenant de différents contextes. Les algorithmes permettent d’extraire des informations, de définir des profils types, non seulement de repérer des comportements suspects mais aussi de les prédire, tout comme sont anticipés des événements ou des tendances : vendre des produits avant de les fabriquer, connaître à quel moment l’internaute sera prêt à passer à l’acte d’achat… Mais ils permettent aussi d’accélérer le séquençage du génome humain ou d’établir une cartographie des différentes formes de maladies dégénératives du cerveau. | * '''La « Vélocité » du [[Big Data]]''' caractérise à la fois la rapidité de production et de traitement des mégadonnées. C’est le « data mining », qui permet de traiter rapidement les masses de données grâce aux algorithmes. Ces outils d’analyse, de plus en plus puissants, sont capables de s’autocorriger (« machine learning »), gèrent des informations qui n’ont plus besoin d’être structurées dans des bases de données, et permettent de détecter des relations entre des données hétérogènes provenant de différents contextes. Les algorithmes permettent d’extraire des informations, de définir des profils types, non seulement de repérer des comportements suspects mais aussi de les prédire, tout comme sont anticipés des événements ou des tendances : vendre des produits avant de les fabriquer, connaître à quel moment l’internaute sera prêt à passer à l’acte d’achat… Mais ils permettent aussi d’accélérer le séquençage du génome humain ou d’établir une cartographie des différentes formes de maladies dégénératives du cerveau. | ||
| + | |||
| + | {{@}} '''Le big data, c’est 3V + 1U''' : Volume, Variété, Vitesse et en plus : '''un usage non destructif de la donnée'''. | ||
| + | Avec ce quatrième critère le Big Data permet de traiter des données pas obligatoirement structurée et ne nécessite pas obligatoirement de les convertir à des formats précis. Ainsi, contrairement au process ETL : “extract, transform and load” la donnée initiale n'étant pas forcément détruite dans le process. | ||
| + | L’approche n'est donc plus limitée à des analyses spécifiques pour des données spécifiques. Elle peut puiser dedans et hors des données existaient dans un système de transaction restreint et utiliser des données qui existent çà et là dans l'univers du monde hyper-connecté, produisant tous ces quintillions de données. Ainsi, le Big Data, en plus d'une simple analyse de données: | ||
| + | – regarde et exploitent les données disponibles (structurée ou non) en dehors du système initial de votre organisation (souvent structuré); | ||
| + | – regarder et exploitent notamment les données accessibles à tous, les fameuses open-data; | ||
| + | – Connecte, croise, les données de façon multidimensionnelle et avec celles dont on dispose déjà. | ||
| + | |||
}}<!-- ******** Fin Fiche Didactique Définition ******************* --> | }}<!-- ******** Fin Fiche Didactique Définition ******************* --> | ||
Version du 7 avril 2020 à 14:01


 Traduction
Traduction

Définition
Domaine, Discipline, Thématique
Définition écrite
- Le Big Data désigne des volumes importants de données très diverses (structurées ou non), traitées et analysées pour extraire des informations qui seront utilisées dans de nombreux domaines. Ces « mégadonnées » (ou encore «données massives ») sont qualifiées de « carburant » ou d’« or noir » car leur valeur alimente l’économie numérique. Certaines dérives font que la technologie du Big Data est notamment très utilisée dans le traitement de données personnelles.
|
|
Définition graphique
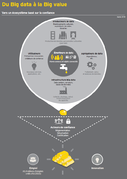
Big Data et Ethique

Comment l'analyse de données crée-t-elle de la valeur ?

Big Data aux Smart Data


{{{AutresMedias}}}
Concepts ou notions associés
Exemples, applications, utilisations
|
Les avantages de l’exploitation du big data sont importants:
L’objectif: diminuer le temps de trajet quotidien de millions de personnes. Une étude similaire, utilisant les données anonymisées des cartes de transport, a été réalisée sur les trajets quotidiens à Londres. Elle permet d’anticiper la congestion des bus et des métros et d’informer les usagers par le biais de comptes Twitter ; bientôt des informations en temps réel pourront être fournies pour leur permettre d’adapter leurs trajets. S’il s’agit dans les deux cas de données anonymisées, celles-ci sont utilisées à une autre fin que celle initialement prévue… Mais le plus préoccupant concerne le respect de la confidentialité des données personnelles.
|
Erreurs ou confusions éventuelles
- Confusion entre ....... et ........
- Confusion entre ....... et ........
- Erreur fréquente: ....................
Questions possibles
Liaisons enseignements et programmes
Idées ou Réflexions liées à son enseignement
Aides et astuces
- ..................
- .................
- ..................
- .................
Education: Autres liens, sites ou portails
- ..................
- ..................
- ..................
Bibliographie
Pour citer cette page: (Data)
ABROUGUI, M & al, 2020. Big Data. In Didaquest [en ligne]. <http:www.didaquest.org/wiki/Big_Data>, consulté le 24, novembre, 2024
- ..................
- ..................
- ..................
- ..................

{kind=link}
{kind=link}