Différences entre versions de « Apprentissage automatique »
De Didaquest
Aller à la navigationAller à la recherche| Ligne 124 : | Ligne 124 : | ||
<!-- Compléter les pointillés et Supprimer les lignes non utilisées --> | <!-- Compléter les pointillés et Supprimer les lignes non utilisées --> | ||
<!-- ****************** Commercez les modifications *********************** --> | <!-- ****************** Commercez les modifications *********************** --> | ||
| + | |||
| + | *L'apprentissage automatique est utilisé dans un large spectre d'applications pour doter des ordinateurs ou des machines de capacité d'analyser des données d'entrée comme : perception de leur environnement (vision, Reconnaissance de formes tels des visages, schémas, segmentation d'image, langages naturels, caractères dactylographiés ou manuscrits ; moteurs de recherche, analyse et indexation d'images et de vidéo, en particulier pour la recherche d'image par le contenu ; aide aux diagnostics, médical notamment, bio-informatique, chémoinformatique ; interfaces cerveau-machine ; détection de fraudes à la carte de crédit, cybersécurité, analyse financière, dont analyse du marché boursier ; classification des séquences d'ADN ; jeu ; génie logiciel ; adaptation de sites Web ; robotique (locomotion de robots, etc.) ; analyse prédictive dans de nombreux domaines (financière, médicale, juridique, judiciaire). | ||
| + | |||
| + | *Un système d'apprentissage automatique peut permettre à un robot ayant la capacité de bouger ses membres, mais ne sachant initialement rien de la coordination des mouvements permettant la marche, d'apprendre à marcher. Le robot commencera par effectuer des mouvements aléatoires, puis, en sélectionnant et privilégiant les mouvements lui permettant d'avancer, mettra peu à peu en place une marche de plus en plus efficace | ||
| + | |||
| + | *La reconnaissance de caractères manuscrits est une tâche complexe car deux caractères similaires ne sont jamais exactement identiques. Il existe des systèmes d'apprentissage automatique qui apprennent à reconnaître des caractères en observant des « exemples », c'est-à-dire des caractères connus. Un des premiers système de ce type est celui de reconnaissance des codes postaux US manuscrits issu des travaux de recherche de Yann Le Cun, un des pionniers du domaine 18,19, et ceux utilisés pour la reconnaissance d'écriture ou OCR. | ||
*La voiture autonome paraît en 2016 réalisable grâce à l’apprentissage automatique et les énormes quantités de données générées par la flotte automobile, de plus en plus connectée. Contrairement aux algorithmes classiques (qui suivent un ensemble de règles prédéterminées), l’apprentissage automatique apprend ses propres règles. | *La voiture autonome paraît en 2016 réalisable grâce à l’apprentissage automatique et les énormes quantités de données générées par la flotte automobile, de plus en plus connectée. Contrairement aux algorithmes classiques (qui suivent un ensemble de règles prédéterminées), l’apprentissage automatique apprend ses propres règles. | ||
| − | + | ||
| − | |||
| − | |||
| − | |||
| − | |||
}}<!--************** Fin Fiche Didactique Explicitations ******************* --> | }}<!--************** Fin Fiche Didactique Explicitations ******************* --> | ||
Version du 18 mars 2022 à 10:43


 Traduction
Traduction

Définition
Domaine, Discipline, Thématique
Définition écrite
- L'apprentissage automatique (en anglais : machine learning), apprentissage artificiel ou apprentissage statistique est un champ d'étude de l'intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune. Plus largement, il concerne la conception, l'analyse, l'optimisation, le développement et l'implémentation de telles méthodes.
- L'apprentissage automatique comporte généralement deux phases. La première consiste à estimer un modèle à partir de données, appelées observations, qui sont disponibles et en nombre fini, lors de la phase de conception du système. L'estimation du modèle consiste à résoudre une tâche pratique, telle que traduire un discours, estimer une densité de probabilité, reconnaître la présence d'un chat dans une photographie ou participer à la conduite d'un véhicule autonome. Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu'ils aient un moyen d'obtenir un retour sur la qualité des résultats produits.
|
Définition graphique
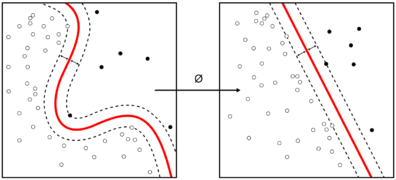
Les machines à noyau sont utilisées pour calculer des fonctions non linéairement séparables
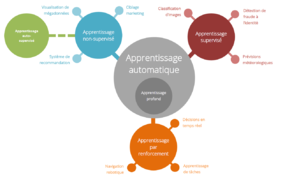
La notion de leartning machine
Systhème de connaissance avec un programme d'apprentissage automatique

Examen du calcul de l’apprentissage dirigé




{{{AutresMedias}}}
Concepts ou notions associés
Exemples, applications, utilisations
|
Erreurs ou confusions éventuelles
- Confusion entre Apprentissage supervisé - Apprentissage non supervisé
- Confusion entre Apprentissage semi-supervisé - Apprentissage partiellement supervisé
- Erreur fréquente: Apprentissage par renforcement
Questions possibles
Liaisons enseignements et programmes
Idées ou Réflexions liées à son enseignement
Aides et astuces
- ..................
- .................
- ..................
- .................
Education: Autres liens, sites ou portails
- ..................
- ..................
- ..................
Bibliographie
Pour citer cette page: (automatique)
ABROUGUI, M & al, 2022. Apprentissage automatique. In Didaquest [en ligne]. <http:www.didaquest.org/wiki/Apprentissage_automatique>, consulté le 21, novembre, 2024
- ..................
- ..................
- ..................
- ..................

{kind=link}
{kind=link}
Catégories :
- Sponsors Education
- L'apprentissage automatique (Concepts)
- Apprentissage machine (Concepts)
- Apprentissage artificiel (Concepts)
- Apprentissage statistique (Concepts)
- L'intelligence artificielle (Concepts)
- Machine Learning (Concepts)
- Apprentissage supervisé (Concepts)
- Boosting (Concepts)
- Bagging (Concepts)
- Régression logistique (Concepts)
- Machine Learning
- L'apprentissage automatique
- Apprentissage machine
- Apprentissage artificiel
- Apprentissage statistique
- Intelligence artificielle
- Algorithme d'apprentissage
- Apprentissage supervisé
- Apprentissage non supervisé
- Apprentissage semi-supervisé
- Concepts
- Apprentissage automatique
- Apprentissage automatique (Concepts)
- Fiche conceptuelle didactique