Différences entre versions de « Apprentissage automatique »
De Didaquest
Aller à la navigationAller à la recherche| Ligne 49 : | Ligne 49 : | ||
<!-- *************** Commercez les modifications *******************--> | <!-- *************** Commercez les modifications *******************--> | ||
| − | *L'apprentissage automatique (en anglais : machine learning), apprentissage artificiel ou apprentissage statistique est un champ d'étude de l'intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune. Plus largement, il concerne la conception, l'analyse, l'optimisation, le développement et l'implémentation de telles méthodes. | + | *[[L'apprentissage automatique]] (en anglais : [[machine learning]]), [[apprentissage artificiel]] ou [[apprentissage statistique]] est un champ d'étude de l'[[intelligence artificielle]] qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune. Plus largement, il concerne la conception, l'analyse, l'optimisation, le développement et l'implémentation de telles méthodes. |
*L'apprentissage automatique comporte généralement deux phases. La première consiste à estimer un modèle à partir de données, appelées observations, qui sont disponibles et en nombre fini, lors de la phase de conception du système. L'estimation du modèle consiste à résoudre une tâche pratique, telle que traduire un discours, estimer une densité de probabilité, reconnaître la présence d'un chat dans une photographie ou participer à la conduite d'un véhicule autonome. Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu'ils aient un moyen d'obtenir un retour sur la qualité des résultats produits. | *L'apprentissage automatique comporte généralement deux phases. La première consiste à estimer un modèle à partir de données, appelées observations, qui sont disponibles et en nombre fini, lors de la phase de conception du système. L'estimation du modèle consiste à résoudre une tâche pratique, telle que traduire un discours, estimer une densité de probabilité, reconnaître la présence d'un chat dans une photographie ou participer à la conduite d'un véhicule autonome. Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu'ils aient un moyen d'obtenir un retour sur la qualité des résultats produits. | ||
Version actuelle datée du 25 mai 2022 à 16:06


 Traduction
Traduction

Définition
Domaine, Discipline, Thématique
Définition écrite
- L'apprentissage automatique (en anglais : machine learning), apprentissage artificiel ou apprentissage statistique est un champ d'étude de l'intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d'« apprendre » à partir de données, c'est-à-dire d'améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune. Plus largement, il concerne la conception, l'analyse, l'optimisation, le développement et l'implémentation de telles méthodes.
- L'apprentissage automatique comporte généralement deux phases. La première consiste à estimer un modèle à partir de données, appelées observations, qui sont disponibles et en nombre fini, lors de la phase de conception du système. L'estimation du modèle consiste à résoudre une tâche pratique, telle que traduire un discours, estimer une densité de probabilité, reconnaître la présence d'un chat dans une photographie ou participer à la conduite d'un véhicule autonome. Cette phase dite « d'apprentissage » ou « d'entraînement » est généralement réalisée préalablement à l'utilisation pratique du modèle. La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d'obtenir le résultat correspondant à la tâche souhaitée. En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu'ils aient un moyen d'obtenir un retour sur la qualité des résultats produits.
|
Définition graphique
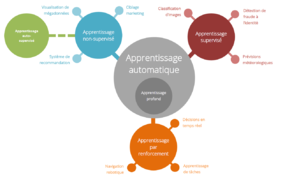
![]() Carte conceptuelle : Apprentissage automatique
Carte conceptuelle : Apprentissage automatique
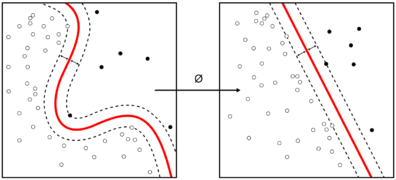
Les machines à noyau sont utilisées pour calculer des fonctions non linéairement séparables
La notion de leartning machine
Systhème de connaissance avec un programme d'apprentissage automatique

Examen du calcul de l’apprentissage dirigé




{{{AutresMedias}}}
Concepts ou notions associés
Exemples, applications, utilisations
|
Erreurs ou confusions éventuelles
- Confusion entre Apprentissage supervisé - Apprentissage non supervisé
- Confusion entre Apprentissage semi-supervisé - Apprentissage partiellement supervisé
- Erreur fréquente: Apprentissage par renforcement
Questions possibles
Liaisons enseignements et programmes
Idées ou Réflexions liées à son enseignement
- L'apprentissage automatique s'intègre au sein de l’intégration de l’IA qui a une grande influance dans le secteur d'éducation.
L’IA, nous l’avons vu, est en émergence dans le domaine de l’éducation, notamment avec les applications à destination tant des apprenants que des enseignants. La cartographie IA en éducation réalisée nous montre la diversité des usages actuellement :
- Traitement du langage naturel, comme par exemple Kialo-edu.com5 , qui soutient des activités d’argumentation en classe
- Reconnaissance visuelle, comme dans le cas de Lexplore.com6, qui permet l’analyse de lecture des élèves.
- Reconnaissance vocale, comme RoboTutor, qui s’adapte au niveau des apprenants tant sur des activités de langue que mathématiques
- Systèmes experts; la création de déboires en mathématiques
- Robotique, comme Rubi project
Aides et astuces
- Indicateurs dans le contexte de la classification
- Matrice de confusionUne : matrice de confusion est utilisée pour avoir une image complète de la performance d'un modèle. Elle est définie de la manière suivant.
- Indicateurs principaux : Les indicateurs suivants sont communément utilisés pour évaluer la performance des modèles de classification.
- Courbe ROC : La fonction d'efficacité du récepteur, plus fréquemment appelée courbe ROC (de l'anglais Receiver Operating Curve), est une courbe représentant le taux de True Positives en fonction de taux de False Positives et obtenue en faisant varier le seuil.
- AUC : L'aire sous la courbe ROC, aussi notée AUC (de l'anglais Area Under the Curve) ou AUROC (de l'anglais Area Under the ROC).
- Indicateurs dans le contexte de la régression
- Indicateurs de baseÉtant donné un modèle de régression ff, les indicateurs suivants sont communément utilisés pour évaluer la performance d'un modèle.
- Coefficient de déterminationLe coefficient de détermination, souvent noté R^2R2 ou r^2r2 , donne une mesure sur la qualité du modèle
- Indicateurs principauxLes indicateurs suivants sont communément utilisés pour évaluer la performance des modèles de régression.
Education: Autres liens, sites ou portails
Bibliographie
Pour citer cette page: (automatique)
ABROUGUI, M & al, 2022. Apprentissage automatique. In Didaquest [en ligne]. <http:www.didaquest.org/wiki/Apprentissage_automatique>, consulté le 16, février, 2025
- « apprentissage automatique » [archive], Le Grand Dictionnaire terminologique, Office québécois de la langue française (consulté le 28 janvier 2020).
- Commission d'enrichissement de la langue française, « Vocabulaire de l’intelligence artificielle (liste de termes, expressions et définitions adoptés) », Journal officiel de la République française no 0285 du 9 décembre 2018 [lire en ligne [archive]] [PDF].
- « classement » est la traduction correcte du terme anglais classification ; la « classification » française correspond plutôt au clustering en anglais. Voir par exemple la BDL [archive] québécoise.
- https://www.cs.virginia.edu/~robins/Turing_Paper_1936.pdf [archive]
- https://www.csee.umbc.edu/courses/471/papers/turing.pdf [archive]
- (en) « Neural Networks » [archive], sur standford.edu (consulté le 11 mai 2018).
- (en) « Arthur Lee Samuel » [archive], sur history.computer.org (consulté le 11 mai 2018).
- (en) « Arthur Samuel: Pioneer in Machine Learning » [archive], sur standford.edu (consulté le 11 mai 2018).
- (en-US) « IBM100 - Deep Blue » [archive], sur www-03.ibm.com, 7 mars 2012 (consulté le 11 mai 2018).
- (en-US) John Markoff, « On ‘Jeopardy!’ Watson Win Is All but Trivial », The New York Times, 16 février 2011 (ISSN 0362-4331, lire en ligne [archive], consulté le 11 mai 2018).
- (en) « Google's Artificial Brain Learns to Find Cat Videos » [archive], sur wired.com, 20 juin 2012 (consulté le 11 mai 2018).
- (en) Jamie Condliffe, « Google's Artificial Brain Loves to Watch Cat Videos » [archive], sur gizmodo.com, 26 juin 2012 (consulté le 11 mai 2018).
- (en) Doug Aamoth, « Interview with Eugene Goostman, the Fake Kid Who Passed the Turing Test » [archive], sur time.com, 9 juin 2014 (consulté le 11 mai 2018).
- (en) Christof Koch, « How the Computer Beat the Go Master » [archive], sur scientificamerican.com, 19 mars 2016 (consulté le 11 mai 2018).
- (en) Jamie Condliffe, « AI Has Beaten Humans at Lip-reading » [archive], sur technologyreview.com, 21 novembre 2016 (consulté le 11 mai 2018).
- (en) « A history of machine learning » [archive], sur cloud.withgoogle.com (consulté le 11 mai 2018).
- Yann Le Cun sur l'apprentissage prédictif [archive], 2016.
- « Retour d'expérience sur l'étude de la base MNIST pour la reconnaissance de chiffres manuscrits

{kind=link}
{kind=link}
Catégories :
- Sponsors Education
- Apprentissage automatique (Concepts)
- Apprentissage machine (Concepts)
- Apprentissage artificiel (Concepts)
- Apprentissage statistique (Concepts)
- Intelligence artificielle (Concepts)
- Machine Learning (Concepts)
- Apprentissage supervisé (Concepts)
- Boosting (Concepts)
- Bagging (Concepts)
- Régression logistique (Concepts)
- Machine Learning
- L'apprentissage automatique
- Apprentissage machine
- Apprentissage artificiel
- Apprentissage statistique
- Intelligence artificielle
- Algorithme d'apprentissage
- Apprentissage supervisé
- Apprentissage non supervisé
- Apprentissage semi-supervisé
- Concepts
- Apprentissage automatique
- Fiche conceptuelle didactique